

Manus
是中国的创业公司Monica发布的全球首款通用Agent(自主智能体)产品
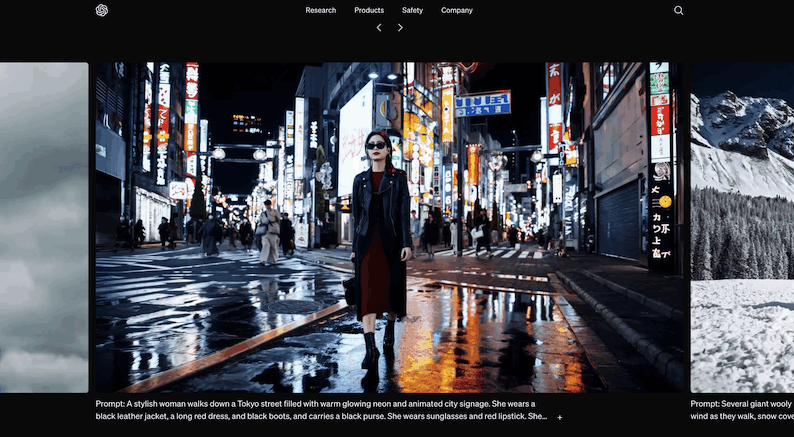
Sora 是由 OpenAI 开发的一种人工智能模型,能够根据文本指令创建真实感和想象力丰富的视频场景。
Sora 是 OpenAI 推出的一款创新的文本到视频的 AI 模型,它通过先进的技术能够将用户的文本描述转化为视觉内容。Sora 的主要功能包括视频生成、视频扩展和多角色、多动作的视频创作。尽管模型仍在不断改进中,但其在生成复杂场景和保持视觉风格一致性方面已经展现出显著的能力。同时,Sora 也注重安全性,通过多种措施确保生成的内容符合使用政策。Sora 的开发是 OpenAI 向实现通用人工智能(AGI)迈出的重要一步。




